Sie scrollen durch eine KI-Kunst-Galerie — DeviantArt, ArtStation, Twitter oder einen Discord-Server — und bleiben bei einem Bild stehen, das genau dem entspricht, was Sie schon lange versuchen zu erstellen. Die Beleuchtung ist perfekt. Die Komposition ist atemberaubend. Der Stil ist genau das, was Sie wollen.
Das Problem: Sie kennen den Prompt nicht. Und selbst wenn Sie ihn kennen würden — würde ein einfaches Kopieren tatsächlich dasselbe Ergebnis liefern?
Das ist die Kunst des Reverse Prompt Engineering — die visuelle DNA eines Bildes zu extrahieren und in Textanweisungen zurückzuübersetzen. Gut beherrscht, ist es eine der mächtigsten Fähigkeiten, die ein KI-Künstler entwickeln kann. Dieser Leitfaden führt Sie durch den gesamten Prozess.
Warum Reverse Engineering funktioniert (und seine Grenzen)
KI-Bildgeneratoren werden darauf trainiert, Text-Prompts visuellen Ausgaben zuzuordnen. Reverse Engineering nutzt diese Beziehung: Wenn ein Modell von Text → Bild gehen kann, dann können Sie mit den richtigen Werkzeugen auch von Bild → Text-Annäherung gehen.
Es ist nicht perfekt. KI-Generatoren haben eine inhärente Zufälligkeit (gesteuert durch Seed-Werte), und derselbe Prompt erzeugt Variationen, keine identischen Kopien. Aber Reverse Engineering bringt Sie nah genug heran, um:
- Die allgemeine Ästhetik und Stimmung nachzubilden
- Denselben Stil auf andere Motive anzuwenden
- Auf einem bestehenden visuellen Stil mit eigenen kreativen Ergänzungen aufzubauen
- Zu verstehen, wie bestimmte visuelle Effekte erzielt werden
Methode 1: Ein KI-Bild-zu-Prompt-Tool verwenden
Der schnellste Ansatz ist die Verwendung eines speziellen Bild-zu-Prompt-Konverters wie ImageToPrompt. Diese Tools nutzen Vision-KI, um Ihr Referenzbild zu analysieren und einen vollständigen Prompt zu generieren, der für Ihr Zielmodell formatiert ist.
Der Workflow:
- Speichern Sie das Bild, das Sie rekonstruieren möchten
- Laden Sie es auf ImageToPrompt.dev hoch
- Wählen Sie das KI-Modell, das Sie verwenden möchten (Midjourney, Stable Diffusion, Flux usw.)
- Erhalten Sie in Sekundenschnelle einen gebrauchsfertigen Prompt
Dies ist der Ansatz, den die meisten professionellen KI-Künstler als Ausgangspunkt nutzen. Er übernimmt die zeitaufwändige Arbeit der Identifizierung und Beschreibung visueller Details, sodass Sie sich auf die Verfeinerung konzentrieren können.
Probieren Sie es selbst — laden Sie ein beliebiges Bild hoch und erhalten Sie in Sekunden einen optimierten KI-Prompt.
Kostenlos testen →Methode 2: Manuelle visuelle Zerlegung
Auch mit KI-Unterstützung macht Sie das Verständnis der manuellen Bildzerlegung zu einem deutlich besseren Prompt-Ingenieur. So analysieren Sie ein Bild systematisch:
Das Motiv analysieren
Beginnen Sie mit dem Offensichtlichen: Was ist im Bild? Seien Sie spezifisch. „Frau“ ist schwach. „Eine junge Frau Mitte 20 mit schulterlangem dunklem Haar, die eine Vintage-Lederjacke trägt“ gibt der KI wesentlich mehr Material.
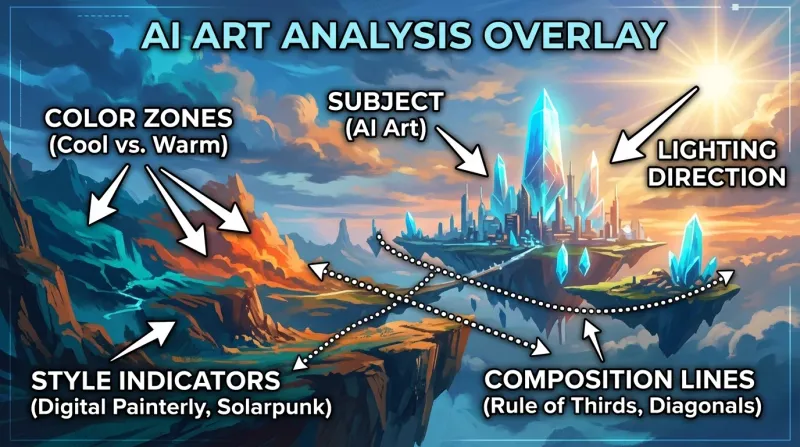
Visuelle Zerlegung: Jedes Element eines Bildes identifizieren, bevor es in Prompt-Sprache übersetzt wird. Klicken Sie für die volle Größe.
Die Beleuchtung lesen
Beleuchtung ist eines der wirkungsmächtigsten Elemente in jedem Bild. Stellen Sie sich diese Fragen:
- Wo befindet sich die Lichtquelle? (Frontlicht, Seitenlicht, Gegenlicht, Rim-Lighting)
- Ist das Licht hart oder weich? (harsches direktes Sonnenlicht vs. diffuses Licht bei bedecktem Himmel)
- Welche Farbe hat das Licht? (warme Golden Hour, kühle blaue Dämmerung, neutrales Studiolicht)
- Gibt es sekundäre Lichtquellen oder farbige Gels?
- Wie dramatisch sind die Schatten?
Stil und Medium identifizieren
Ist das Bild fotografisch oder gemalt? Wenn fotografisch: Welche Kamera, welches Objektiv? Wenn gemalt: Welches Medium (Öl, Aquarell, Digital), welcher Künstlerstil (impressionistisch, hyperrealistisch, Anime)?
Nützliche Stil-Deskriptoren sind: cinematic, hyperrealistic, painterly, concept art, illustration, watercolor, cel shading, photorealism, editorial
Die Farbpalette erfassen
KI-Generatoren reagieren stark auf Farbbeschreibungen. Identifizieren Sie:
- Dominante Farben (2–4 Farben, die das Bild definieren)
- Gesamttemperatur (warm, kühl oder neutral)
- Sättigung (leuchtend, gedämpft, entsättigt)
- Kontrastniveau (hoher Kontrast, flach, niedriger Kontrast)
Die Komposition beschreiben
Wie ist das Bild gerahmt? Gängige Kompositionsbeschreibungen:
- Einstellungsgröße: Nahaufnahme, halbnahe Aufnahme, Totale, Luftaufnahme, Froschperspektive
- Tiefenschärfe: Bokeh, geringe Schärfentiefe, Tiefenschärfe
- Drittel-Regel, zentrierte Komposition, Leitlinien
- Negativraum
Methode 3: Beides kombinieren — Der professionelle Workflow
Der effektivste Ansatz kombiniert KI-Analyse mit manueller Verfeinerung. Hier ist der vollständige Workflow, den professionelle KI-Künstler verwenden:
Schritt 1: Einen Basis-Prompt generieren
Laden Sie Ihr Referenzbild auf ImageToPrompt hoch und generieren Sie einen ersten Prompt. Das bringt Sie etwa zu 80 % ans Ziel und dauert in der Regel weniger als 30 Sekunden.
Schritt 2: Manuell prüfen und annotieren
Betrachten Sie den generierten Prompt kritisch. Vergleichen Sie ihn mit dem Bild. Was fehlt? Was ist falsch? Spezifische Punkte zum Überprüfen:
- Wird die Beleuchtung genau beschrieben?
- Passt die Stilbeschreibung zu dem, was Sie sehen?
- Fehlen wichtige kompositorische Elemente?
- Gibt es dominante Farben, die nicht erwähnt werden?
Schritt 3: Künstler-Referenzen hinzufügen (optional)
Bei stilisierten Bildern kann das Hinzufügen eines Künstlernamens die Ergebnisse dramatisch verbessern. „In the style of Greg Rutkowski“ oder „in the style of Makoto Shinkai“ signalisiert dem Modell ein vollständiges visuelles Vokabular. Nutzen Sie dies ethisch — referenzieren Sie den Stil, nicht spezifische Werke.
Schritt 4: Testen und iterieren
Generieren Sie 4–8 Varianten mit Ihrem verfeinerten Prompt. Vergleichen Sie sie mit Ihrer Referenz. Identifizieren Sie die größten Abweichungen und passen Sie den Prompt an, um sie zu schließen. Wiederholen Sie, bis Sie zufrieden sind.
Vollständiges Beispiel: Reverse Engineering eines Bildes
Gehen wir den gesamten Prozess an einem einzelnen Bild durch — wir kombinieren automatisierte Analyse mit manueller Verfeinerung, um einen Prompt zu erstellen, der das Ergebnis tatsächlich nachbildet.

Das Referenzbild, das wir per Reverse Engineering rekonstruieren. Klicken Sie für die volle Größe.
Schritt 1: Automatisierte Analyse
Nach dem Hochladen auf ImageToPrompt mit ausgewähltem Midjourney generierte das Tool:
dramatic fantasy portrait of a female warrior, battle-worn armor with intricate engravings, fierce expression, rim lighting from behind with warm orange glow, particle effects and embers, dark atmospheric background, cinematic concept art, digital painting, highly detailed --ar 2:3 --v 6.1 --style raw --q 2
Schritt 2: Manuelle Beobachtungen
Bei der Überprüfung des automatisierten Ergebnisses im Vergleich zum Originalbild fielen zwei Dinge auf. Erstens hatte die KI den spezifischen Farbkontrast nicht erfasst — die Rüstung hatte einen Grünspan-Ton (gealtertes Kupfergrün), der nicht erwähnt wurde. Zweitens war der Hintergrund nicht einfach „dunkel“ — er hatte eine rauchige, fast vulkanische Atmosphäre mit sichtbaren Aschepartikeln. Beides fand sich nicht im ersten Prompt wieder.
Schritt 3: Der verfeinerte Prompt
Nach Hinzufügen der fehlenden Elemente und Anpassung der Gewichtung:
dramatic fantasy portrait of a female warrior, battle-worn armor with verdigris patina and intricate engravings, fierce determined expression, rim lighting from behind with warm volcanic orange glow, ash particles and floating embers, smoky atmospheric background with volcanic haze, cinematic concept art, digital painting, highly detailed, deep shadow contrast --ar 2:3 --v 6.1 --style raw --q 2

Ergebnis mit dem verfeinerten Prompt. Der Grünspan-Ton und die vulkanische Atmosphäre sind nun vorhanden.
Die beiden Ergänzungen — Grünspan-Patina und vulkanische Atmosphäre — haben die Farbgeschichte des Bildes grundlegend verändert. Das ist es, was manuelle Beobachtung zur automatisierten Analyse beiträgt: die spezifischen Details, die ein Bild unverwechselbar statt generisch machen.
Reverse-Engineering-Tipps nach Modell
Midjourney-Bilder rekonstruieren
Midjourney hat eine unverwechselbare Ästhetik — präzise Details mit malerischen Qualitäten. Beim Reverse Engineering von Midjourney-Bildern sollten Sie Midjourney-spezifische Parameter einbeziehen: --style raw für weniger stilisierte Ausgabe, oder --v 6.1 für die neueste Version. Fügen Sie --chaos 15-25 hinzu, wenn Sie mehr Variation in Ihren Ergebnissen wünschen.
Stable-Diffusion-Bilder rekonstruieren
SD-Bilder haben oft erkennbare Merkmale: Bestimmte Modell-Checkpoints erzeugen charakteristische Artefakte. Wenn Sie wissen, dass das Bild mit SDXL erstellt wurde, verwenden Sie einen SDXL-Checkpoint. Verwenden Sie einen starken negativen Prompt, um gängige SD-Probleme zu vermeiden: blurry, low quality, bad anatomy, watermark, text.
Flux-Bilder rekonstruieren
Flux erzeugt extrem fotorealistische Bilder. Beim Reverse Engineering von Flux-Ausgaben konzentrieren Sie sich auf fotografische Sprache: Objektivtypen, Kameraeinstellungen, natürliche Beleuchtungsbeschreibungen. Flux reagiert gut auf technische Fotografieterminologie.
Gleiches Bild, verschiedene Modelle
Dasselbe Referenzbild erzeugt je nach gewähltem KI-Modell sehr unterschiedliche Prompts. Hier sehen Sie, warum das wichtig ist und wie die Unterschiede in der Praxis aussehen.

Midjourney
dramatic portrait, strong directional lighting, deep shadows, intense gaze, cinematic photography style --ar 2:3 --v 6.1 --style raw
Stable Diffusion
(photorealistic:1.2), dramatic portrait, (strong rim lighting:1.3), deep shadows, (intense gaze:1.1), professional photography Negativ: blurry, low quality, deformed, bad anatomy, watermark
Flux
High-resolution photograph of a person in dramatic portrait lighting. Strong rim light from the left creates deep shadows. Shot with Canon EOS R5, 85mm f/1.4, shallow depth of field, cinematic color grading.
DALL·E 3
A dramatic portrait photograph with strong directional lighting creating deep shadows on one side of the face. The subject has an intense, direct gaze. Cinematic, professional quality with shallow depth of field.
Jeder Prompt erfasst dasselbe Bild, aber in der nativen Sprache seines Modells. Midjourney verwendet knappe Deskriptoren und Parameter. Stable Diffusion verwendet gewichtete Syntax und einen negativen Prompt. Flux verwendet fotografische/technische Sprache. DALL·E 3 verwendet vollständige natürliche Sätze. Derselbe visuelle Inhalt, vier verschiedene Formate.
Ethische Überlegungen
Das Reverse Engineering von KI-Kunst ist generell unproblematisch — Sie arbeiten innerhalb des Trainingsparadigmas, in dem diese Modelle operieren. Dennoch einige wichtige Punkte:
- Geben Sie die KI-Kunst anderer nicht als Ihre eigene aus. Reverse Engineering zum Lernen ist in Ordnung; das Ergebnis als eigene Originalkreation auszugeben, ohne die Quelle zu nennen, ist irreführend.
- Seien Sie vorsichtig mit echten Fotos von Personen. Einen Prompt aus einem Foto zu extrahieren und dann KI-Bilder einer bestimmten realen Person zu generieren, wirft ernste ethische und rechtliche Fragen auf.
- Prüfen Sie die Nutzungsbedingungen der Plattformen. Einige Plattformen verbieten es, ihre KI-generierten Bilder als Trainingsdaten oder Reverse-Engineering-Eingaben zu verwenden. Lesen Sie die Bedingungen, bevor Sie fortfahren.
Fortgeschrittene Technik: Stiltransfer per Prompt
Sobald Sie einen guten Stil-Prompt aus einem Referenzbild extrahiert haben, können Sie ihn auf jedes beliebige Motiv anwenden. Das nennt man promptbasierten Stiltransfer, und es ist eine der kreativsten Anwendungen des Reverse Engineering.
Beispiel: Sie rekonstruieren ein wunderschön beleuchtetes Golden-Hour-Porträt und erhalten einen Prompt wie: „cinematic portrait photography, golden hour rim lighting, shallow depth of field, warm amber and rust tones, film grain, Canon 85mm f/1.4“
Ersetzen Sie nun das Porträt-Motiv durch etwas Beliebiges: ein Gebäude, eine Landschaft, ein Stillleben, ein Tier. Die Beleuchtungs- und Stilinformationen übertragen sich auf das neue Motiv und verleihen Ihnen eine konsistente Ästhetik über sehr unterschiedliche Bilder hinweg.
Starten Sie Reverse Engineering in Sekunden
Laden Sie ein beliebiges Bild auf ImageToPrompt hoch und erhalten Sie einen vollständigen, modellspezifischen Prompt, der sofort in Midjourney, Stable Diffusion oder Flux einsetzbar ist.
Kostenlosen KI-Prompt-Generator testen →